On-device diffusion plugins for conditioned text-to-image generation
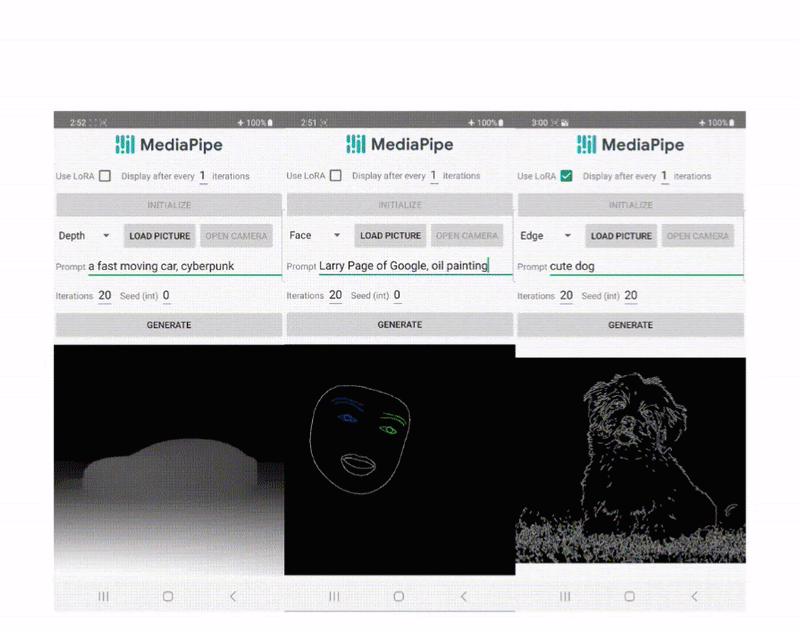
On-device Diffusion Plugins for Conditioned Text-to-Image Generation
- The MediaPipe diffusion plugin is designed to make conditioned text-to-image generation efficient, customizable, and scalable.
- The plugin is plugable, trained from scratch, and portable, allowing it to be easily connected to a pre-trained base model and run on mobile devices with negligible cost compared to base model inference.
- The diffusion plugin extracts multiscale features from a conditioning image and adds them to the encoder of a diffusion model at corresponding levels.
- Examples of plugins developed include MediaPipe Face Landmark, MediaPipe Holistic Landmark, depth maps, and Canny edge for text-to-image generation.
- Both ControlNet and the MediaPipe diffusion plugin offer control over text-to-image generation with given conditions.
- Quantitative evaluation shows that both ControlNet and the MediaPipe diffusion plugin produce better sample quality than the base model, in terms of FID and CLIP scores.
- The MediaPipe diffusion plugin provides comparable performance to ControlNet but with lower inference time on mobile devices.
Conclusion
The MediaPipe diffusion plugin is a portable on-device model that allows for efficient and customizable text-to-image generation with control. It significantly improves sample quality compared to the base model and offers comparable performance to ControlNet while maintaining low inference time on mobile devices.