Unlocking the Power of Enterprise-Ready LLMs with NVIDIA NeMo
Unlocking the Power of Enterprise-Ready LLMs with NVIDIA NeMo
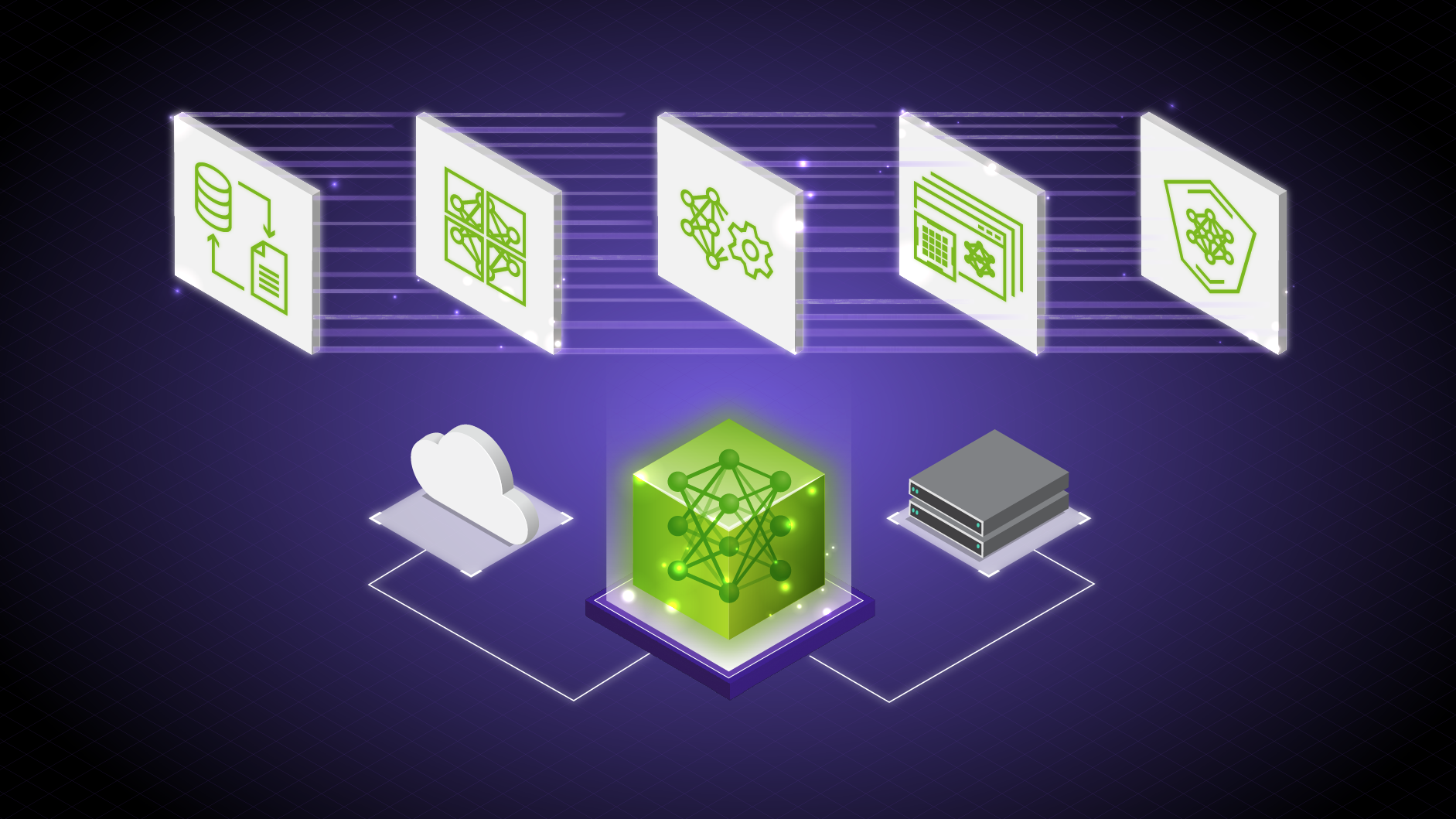
NVIDIA NeMo is an end-to-end platform designed to streamline the development and deployment of large language models (LLMs) for enterprises. It provides a comprehensive framework for building customized, enterprise-grade generative AI models, making it easier than ever to leverage the power of AI in various applications.
End-to-End Platform for Production-Ready Generative AI
The NeMo framework offers a complete set of tools and resources for creating LLMs, including data curation, distributed training, pretrained models, and accelerated inference. With the help of NeMo, enterprises can accelerate the development process and achieve seamless integration of AI capabilities.
Data Curation
In the world of AI, extensive datasets are essential for building robust LLMs. NeMo's Data Curator tool simplifies the process of curating and managing data for training LLMs. One of its key features is deduplication, which helps eliminate redundant data. Data Curator is available as part of the NeMo training container on the NVIDIA GPU Cloud (NGC).
Distributed Training at Scale
NeMo allows for distributed training and advanced parallelism, enabling seamless multi-node and multi-GPU training. By dividing the model and training data, NeMo significantly reduces training time and enhances overall productivity. This parallelism feature is at the core of NeMo's framework, ensuring efficient and scalable training for enterprise-grade LLMs.
Pretrained Models for Customization
While some use cases require training LLMs from scratch, many organizations leverage pretrained models as a starting point for customization. NeMo offers a variety of techniques for refining generic, pretrained LLMs to suit specialized use cases. Prompt engineering is an efficient method that allows the reuse of pretrained models for multiple downstream tasks without fine-tuning the entire model. NeMo also provides p-tuning and prompt tuning, which are parameter-efficient fine-tuning techniques that selectively update only a few parameters of the LLM. These techniques are optimized for multi-GPU and multi-node environments, enabling accelerated training and customization.
Guardrails
As part of the NVIDIA AI Enterprise software suite, NeMo ensures that organizations have the necessary guardrails to deploy LLMs in a secure and compliant manner. This includes tools for monitoring and managing LLMs, as well as ensuring data privacy and security throughout the deployment process.
In conclusion, NVIDIA NeMo provides a comprehensive platform for enterprises to harness the power of LLMs. With its end-to-end capabilities, data curation tools, distributed training, pretrained models, and guardrails for deployment, NeMo simplifies the development and integration of AI capabilities, enabling organizations to unlock the full potential of generative AI.